Original Paper (arXiv:2405.10808)
1. The Problem
The main problem we face in training LLMs for discriminative tasks, such as classification, is the cost of data labeling. Every data point needs manual annotation by domain experts, and that’s the real bottleneck. I have personally faced this in my own experience working with NASA IMPACT when developing classification models. The most painful point was to wait for the SMEs to label the data which caused long delays - waiting weeks or even months before we could train or retrain a model.
The Traditional Solution:
The usual solution to bring down labeling costs is Active Learning (AL). It lets the model select which samples are most valuable to label, typically based on uncertainty. However, these methods still face two major bottlenecks:
- Cold-Start Problem - The model cannot judge which samples are important without some initial labeled data.
- Training Delay - Conventional AL retrains models after every selection cycle, slowing down the annotation process.
2. What ActiveLLM Proposes
ActiveLLM proposed using instruction-tuned LLMs (like GPT-4 or Mistral Large) as query models in the active learning loop. Instead of repeatedly retraining, the LLM selects high-impact instances to be labeled from a set of unlabeled examples - no initial labeled data and no iterative training needed.
The paper evaluates two modes:
- Few-Shot Mode (main focus)
- Non-Few-Shot/Iterative Mode
In this review, we focus on the few-shot setting, which is the core contribution of the paper. The non-few-shot mode is used to demonstrate that ActiveLLM can scale to larger datasets and also help other AL methods overcome their cold-start limitations.
3. How It Works
- Unlabeled Data Pool - A set of examples without labels.
- Prompt an LLM - The LLM receives a task description and a batch of unlabeled data.
- LLM Selection - The model selects examples that are diverse or ambiguous.
- Human Annotation - Only those selected examples are labeled by annotators.
- Successor Training - A smaller transformer (like BERT) is fine-tuned on that subset.
Key design note: Both batch size (how many unlabeled examples the LLM sees at once) and selection size (how many examples the LLM picks for human labeling) are treated as hyperparameters - optimized to balance context length and selection quality. The successor model’s training epochs (25) are also tuned for stability in low-data environment.
4. Key Findings
| Parameter | Finding | Explanation |
|---|---|---|
| Prompt Strategy | “Think step by step” (Chain-of-Thought) works best | CoT helps LLM reason over examples without inflating context too much. |
| Batch Size (context limit) | 200 unlabeled examples per prompt gives optimal results | Larger context hurts performance due to LLM’s reasoning degradation with long inputs. |
| Selection Size | Selecting 32 examples per round gives best accuracy | Performance drops between 32-90; increases again after 90 due to larger training data. |
| LLMs Tested | GPT-4, GPT-3.5, o1, Mistral Large, Llama 3, Gemini Ultra, Mixtral | GPT-4 and GPT-3.5 consistently best; Mistral performs better on shorter texts. |
5. Architecture (Best Configuration from the Paper)
Few-Shot Mode (Main Focus):
- LLM (GPT-4) is prompted with 200 unlabeled samples.
- It selects 32 high-impact examples using “Think step by step” reasoning.
- Annotators label those 32 examples.
- BERT/RoBERTa is fine-tuned for 25 epochs.
Non-Few-Shot (Iterative Mode):
- LLM selects 25 examples per iteration, up to ~300 total.
- Used to show ActiveLLM’s ability to overcome the cold-start problem in other AL methods (e.g., BALD, LC, PE).
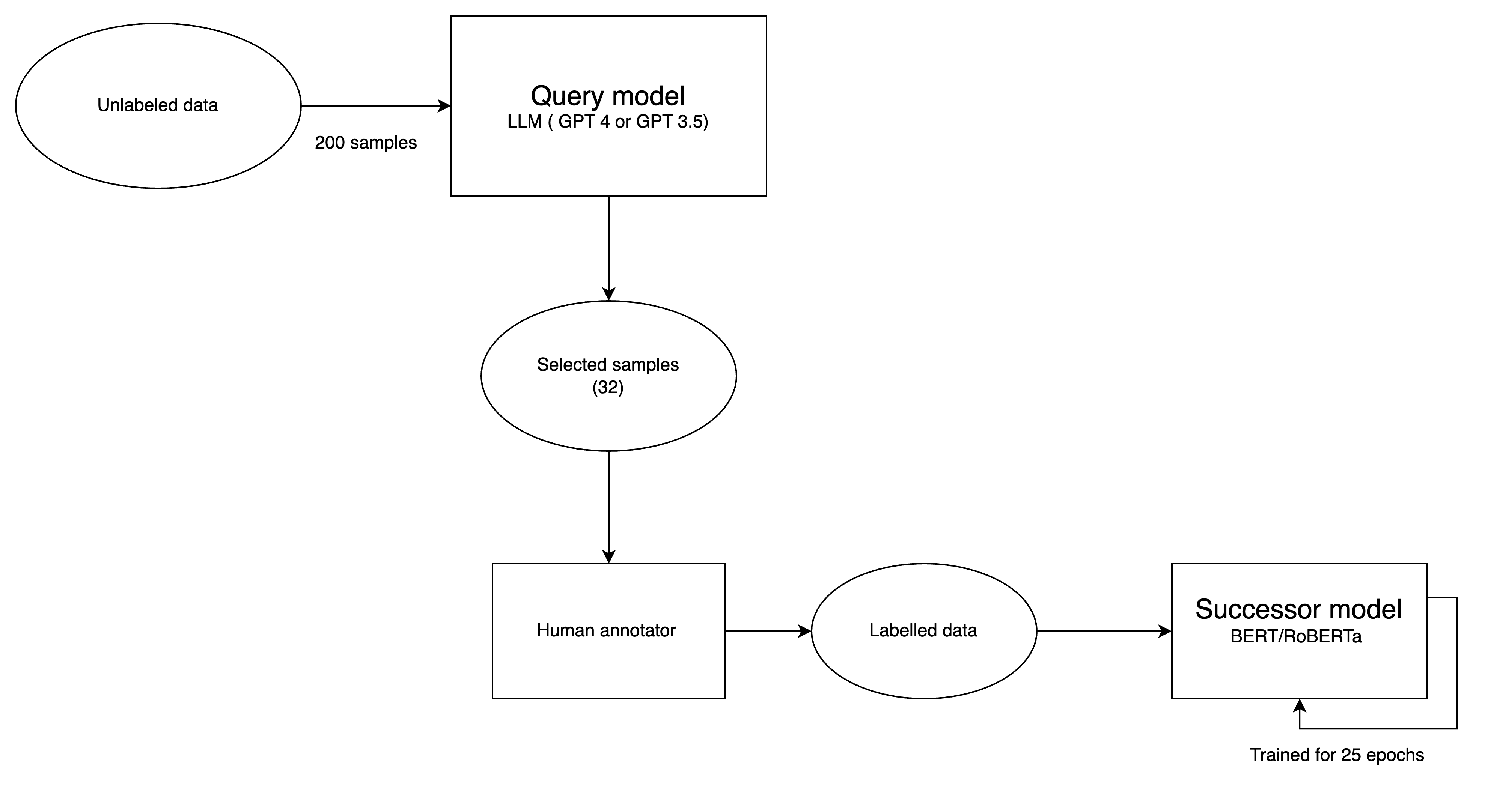 ActiveLLM Architecture (Few shot mode with best performing hyperparameters)
ActiveLLM Architecture (Few shot mode with best performing hyperparameters)
6. Results and Impact
ActiveLLM:
- Solved the cold-start problem - could even initialize other AL strategies for better performance.
- Required seconds per query instead of hours of retraining.
- Outperformed traditional AL strategies (BALD, Least Confidence, Prediction Entropy, Embedding K-Means) in few-shot tasks.
- Boosted performance of few-shot learners like ADAPET and PERFECT by 17-24%.
- Scalable beyond few-shot - can operate iteratively to expand labeled data intelligently for larger datasets.
7. Limitations
- Context length: It limits the number of examples per query.
- Possible data leakage: The data used in the benchmarking could have already been seen by LLM.
- Privacy risks: Using external APIs results in data exposure during annotation
- LLM-dependent variability - Performance differs across GPT-4, Mistral, and Llama as query models
8. Conclusion
ActiveLLM shows a powerful hybrid design - combining the reasoning ability of LLMs with the efficiency of smaller transformer models. It transforms how we approach annotation: instead of training models to guess uncertainty, we use an LLM’s understanding to pick the right data from the start.